Social networking platforms such as Reddit show the total count of users currently viewing a particular post in real-time using a distributed counter. The value of the distributed counter changes when users enter or exit the website.
The distributed counter is a versatile data structure and is typically used for the following use cases 1, 2, 3:
- count the active users of a website or Facebook live video
- count the Facebook likes or reactions
- count the followers of a user on a social networking platform such as Twitter
- count the comments on a post on a social networking platform
- count the events in a monitoring service
- count the recent user activity in the fraud detection system
- count the visits by a particular user for rate-limiting
- count the items viewed or bought by a user in the recommendation service
- count the total visits on every web page of a website to identify the trending web pages
- count the cars available on ride-sharing platforms such as Uber
- count the votes in a real-time voting system
Questions and answers:
- What are the primary use cases of the distributed counter?
- The distributed counter should display the active users on a website in near real-time
- Is the website public facing? Yes, the website is general public-facing
- What is the total count of users on the platform? 1B
- Is the system highly concurrent? Yes,the system must support extremely high concurrency for write and read operations
- What is the average amount of concurrent online users? 100M
- What is the expected peak traffic? 300M
- What is the anticipated read: write ratio of the distributed counter? 10:1
- Should the distributed counter be strongly consistent? No, the distributed counter can be eventually consistent as it does not affect the user experience
- Should the value of the distributed counter be approximate? No, the distributed counter should be accurate
- Are there any limitations to the storage of the distributed counter? The storage used by the distributed counter should be as low as possible
- What should be the operational complexity of the distributed counter? The operational complexity should be kept minimum
Functional Requirements
- The total count of users currently viewing the website or a particular web page should be shown by the distributed counter in real-time
- The value of the distributed must decrement when a user exits the website
- The user receives the count of unread notifications when the subscribed web pages are modified
Non-Functional Requirements
- Highly Available
- Eventually Consistent
- Accurate
- Reliable
- Scalable
- Low Latency
APIs
/:webpage-id/counter
method: GET
accept: application/json, text/html
Response:
```js
{
count: 715,
updated_at: "2030-10-10T12:11:42Z"
}/:webpage-id/counter
method: PUT
content-length: 15
{
action: "increment"
}
Response:
{
count: 812,
updated_at: "2030-10-10T12:11:42Z"
}Which data sets to be used to support this load and all the requirements?
The distributed counter is a replicated integer. The primary benefit of the eventual consistency model is that the database will remain available despite network partitions. The eventual consistency model typically handles conflicts due to concurrent writes on the same item.
Evaluate all the DBs based on bellow criteria
- The database offers high performance on reads and writes
- The database is scalable, durable, and highly available
- The database should support a flexible data model for easy future upgrades
- The learning and development costs should be minimum
SQL:
==Read performance: Read operation is relatively expensive due to the need for table JOIN operations.
Write performance: this approach is not scalable when there are extremely high concurrent writes
**Scalable, Durable and available: ** No
**Flexible data model for easy future upgrades: ** No
Development costs should be minimum:== Yes
one way The server can persist the count update events on distinct records of the database. This approach supports extremely high [concurrent](https://newsletter.systemdesign.one/p/shopify-flash-sale) writes because there is no need for locks. The tradeoff of this approach is slower read queries due to a full table scan and also increased storage costs 2nd way
The counter should be partitioned across multiple nodes for scalability. The database server is replicated to prevent a single point of failure.The distributed counter is also known as a sharded counter.1. multiple counters are initialized in parallel
2. updates to the counter are applied on a random shard using the round-robin algorithm
3. the counter is fetched by summing up the count on every shard through parallel queries
Write improved but read is slowed due to summing up result from multiple shards.
Probabilistic data store
Hash set for each web page to track the count of active users
HyperLogLog data type can be initialized as the counter for a space-efficient but inaccurate counte
NOSQL
Apache Cassandra is an open-source distributed NoSQL database that supports time series data. The nodes in Cassandra communicate with each other using the gossip protocol. Apache Cassandra supports automatic partitioning of the database using consistent hashing. Besides, the leaderless replication makes the database highly available 1. Frequent disk access can become a potential performance bottleneck for reads of the distributed counter using Cassandra. An additional cache layer using Redis can be provisioned with the cache-aside pattern to improve the reads. The downside of this approach is that the data consistency of the distributed counter cannot be guaranteed. The probability of an inaccurate counter is higher when the writes to the database succeed but the cache update fails
KAfka Queue
The message queue can be used to buffer the count update events emitted by the client. The database is asynchronously updated at periodic intervals. This approach is known as the pull model. The message queue should be replicated and checkpointed for high availability and improved fault tolerance. The serverless function will query the message queue at periodic intervals and subsequently update the database.
Issue: The drawbacks of the pull model are increased operational complexity and inaccurate counter due to the asynchronous processing of data. It is also difficult to implement an exactly one-time delivery on the message queue resulting in an inaccurate distributed counter
Redis
Redis offers extremely high performance and throughput with its in-memory data types.The distributed counter is very write-intensive. So, Redis might be a potential choice to build the distributed counter.
Redis can be deployed in the leader-follower replication topology for improved performance. The Redis proxy can be used as the sharding proxy to route the reads to the Redis follower instances and redirect the writes to the Redis leader instance. The hot standby configuration of Redis using replicas improves the fault tolerance of the distributed counter 16. The write-behind cache pattern can be used to asynchronously persist the counter in the relational database for improved durability.
Issue: The count update operations must be idempotent for conflict-free count synchronization across multiple data centers. The drawback of using native data types in Redis is that the count update operations are not idempotent and it is also non-trivial to check whether a command execution on Redis was successful during a network failure,
CRDT Redis enterprice edition: Conflict-free Replicated Data Type
Convergent Replicated Data Types and Commutative Replicated Data Types.
The commutative property of CRDT operations ensures count accuracy among replicas.
- The CRDT is a replicated data type that enables operations to always converge to a consistent state among all replicas nodes
- The CRDT allows lock-free concurrent reads and writes to the distributed counter on any replica node
- The idempotence property in CRDT prevents duplicating items on replication. The order of replication does not matter because the commutative property in CRDT prevents race conditions.
- CRDT-based consistency is a popular approach for multi-leader support because the CRDT offers high throughput, low latency for reads and writes, and tolerates network partitions
- The vector clock is used to identify the causality of count update operations among CRDT replicas
- The CRDT can even accept writes on the nodes that are disconnected from the cluster because the data updates will eventually get merged with other nodes when the network connection is re-established
- the communication layer can use gossip protocol for an efficient replication across CRDT replicas
- The CRDT internally uses mathematically proven rules for automatic and deterministic conflict resolution. Ex
| Property | Formula |
|---|---|
| commutative | a * b = b * a |
| associative | a * ( b * c ) = ( a * b ) * c |
| idempotence | a * a = a |
| Some of the popular CRDTs used in the industry are |
- G-counters (Grow-only): increment-only CRDT counter
- `PN-counters (Positive-Negative): supports incre and decre, read your own write, replicas. can be used for counter.
- G-sets (Grow-only sets)
`We should be using Conflict freee replicated data type for Distributed counter because of its following benifits.
- offers local latency on read and write operations through multi-leader replication
- enables automatic and deterministic conflict resolution
- tolerant to network partitions
- allow concurrent count updates without coordination between replica nodes
- achieves eventual consistency through asynchronous data updates
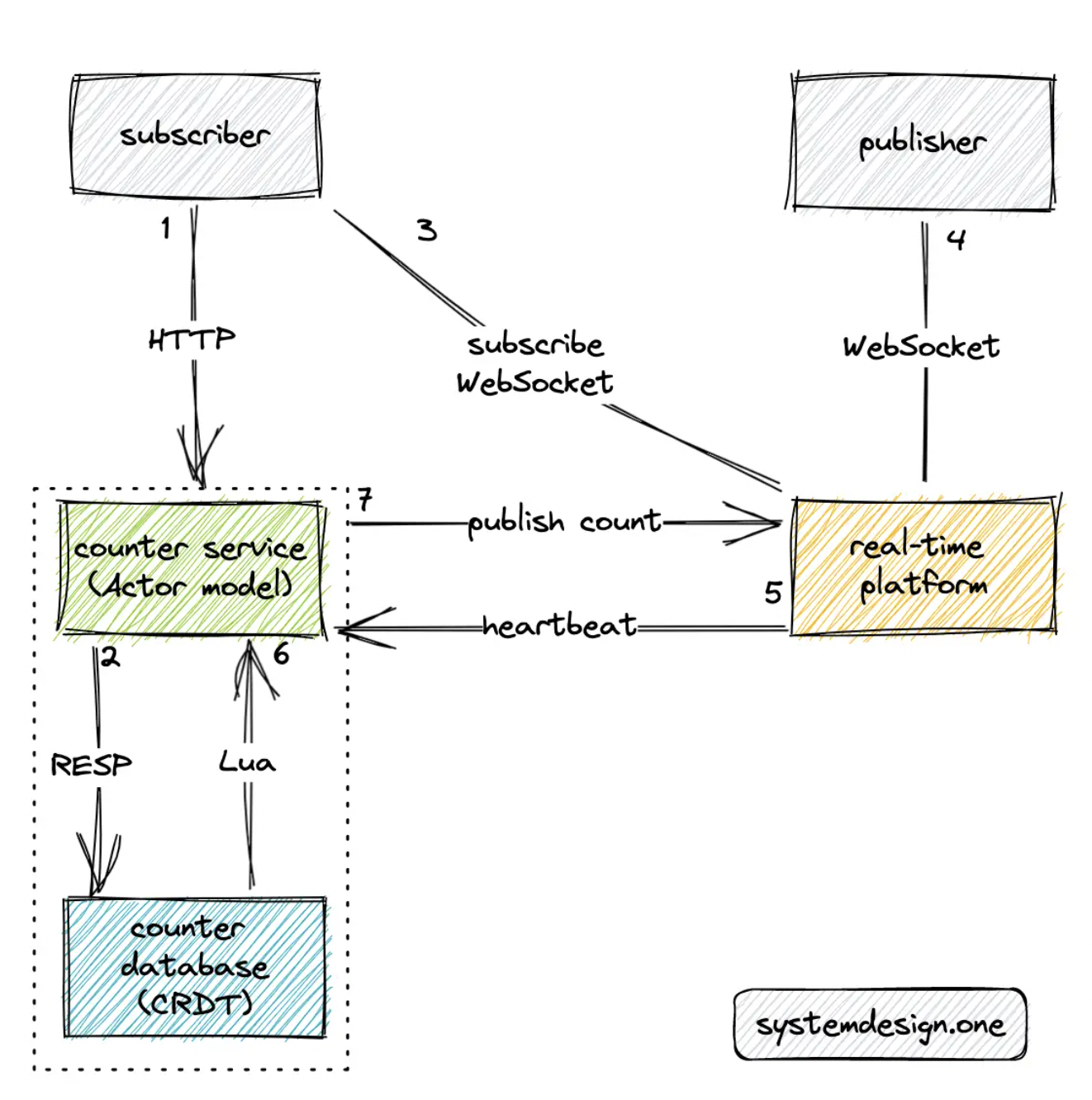
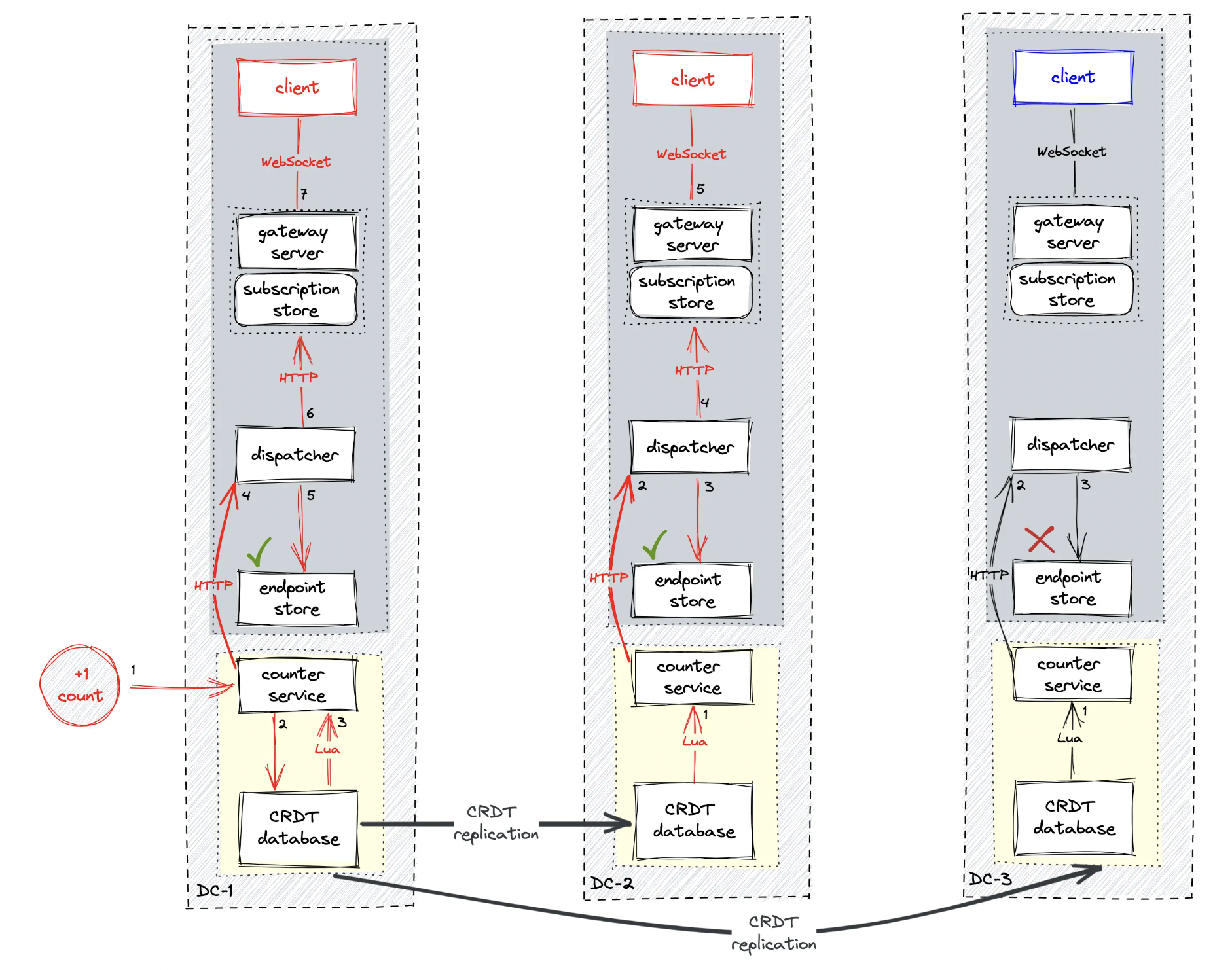
Working
- the subscriber (user) queries the counter service to fetch the count over the HTTP GET method
- the counter service queries the counter database to determine the count
- the user subscribes to the count of a particular web page through the real-time platform and establishes a WebSocket connection
- the publisher (user) establishes a WebSocket connection with the real-time platform
- the real-time platform emits heartbeat signals or http calls to the counter service over UDP at periodic intervals
- the Lua script in the counter database emits an event using the pub-sub pattern whenever there is any update to the distributed counter
- the counter service publishes an event to the real-time platform over the HTTP PUT method
- the real-time platform broadcasts the counter to the subscribers over WebSocket