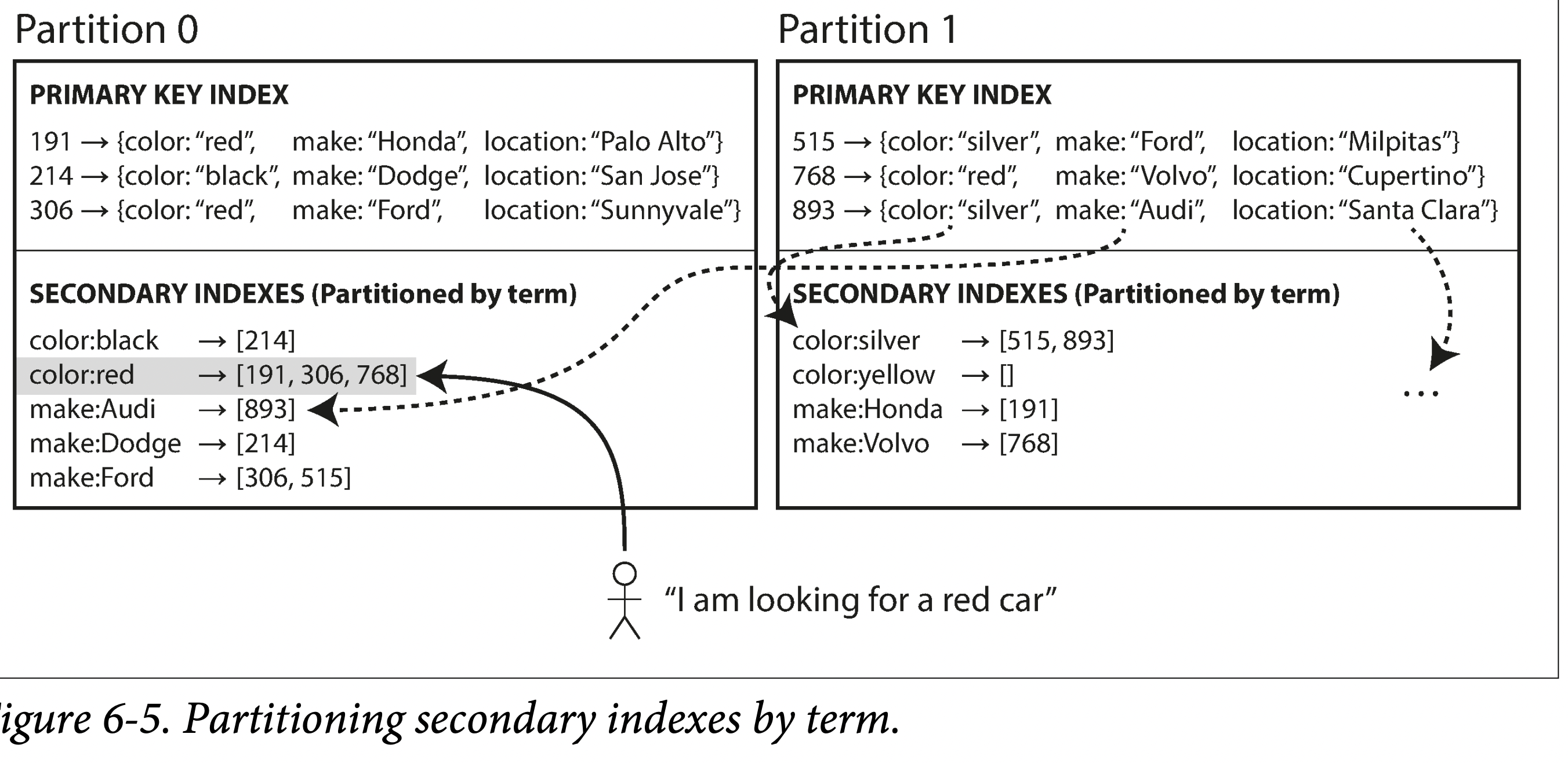
Partitioning becomes more complicated if secondary index needed on the datas. Secondary index is not used to uniquely identify data, but its a other ways of filtering data. Ex: Find all car whose color is red.
Key Value store like HBase, Voldemort avoid secondary indexes because of its added complexity.
There are two ways to partition based on secondary index
- Partitioning Secondary Indexes by Documents. (local indexes), where the secondary indexes are stored in the same partition as the primary key and value. This means that only a single partition needs to be updated on write, but a read of the secondary index requires a scatter/gather across all partitions.
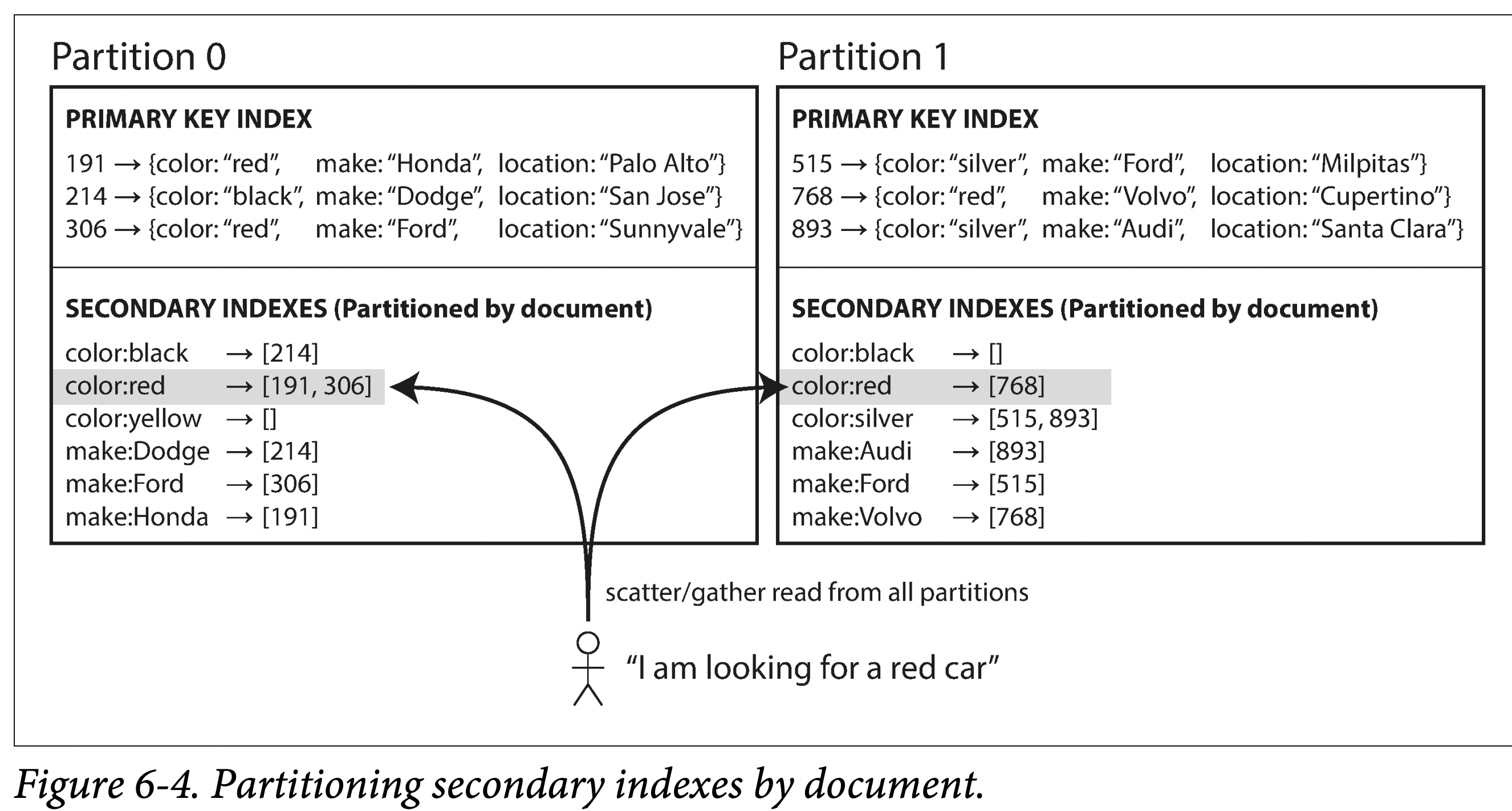
- Partitioning Secondary Indexes by Terms.
(global indexes), where the secondary indexes are partitioned separately, using the indexed values. An entry in the secondary index may include records from all partitions of the primary key. When a document is writ‐ ten, several partitions of the secondary index need to be updated; however, a read can be served from a single partition.