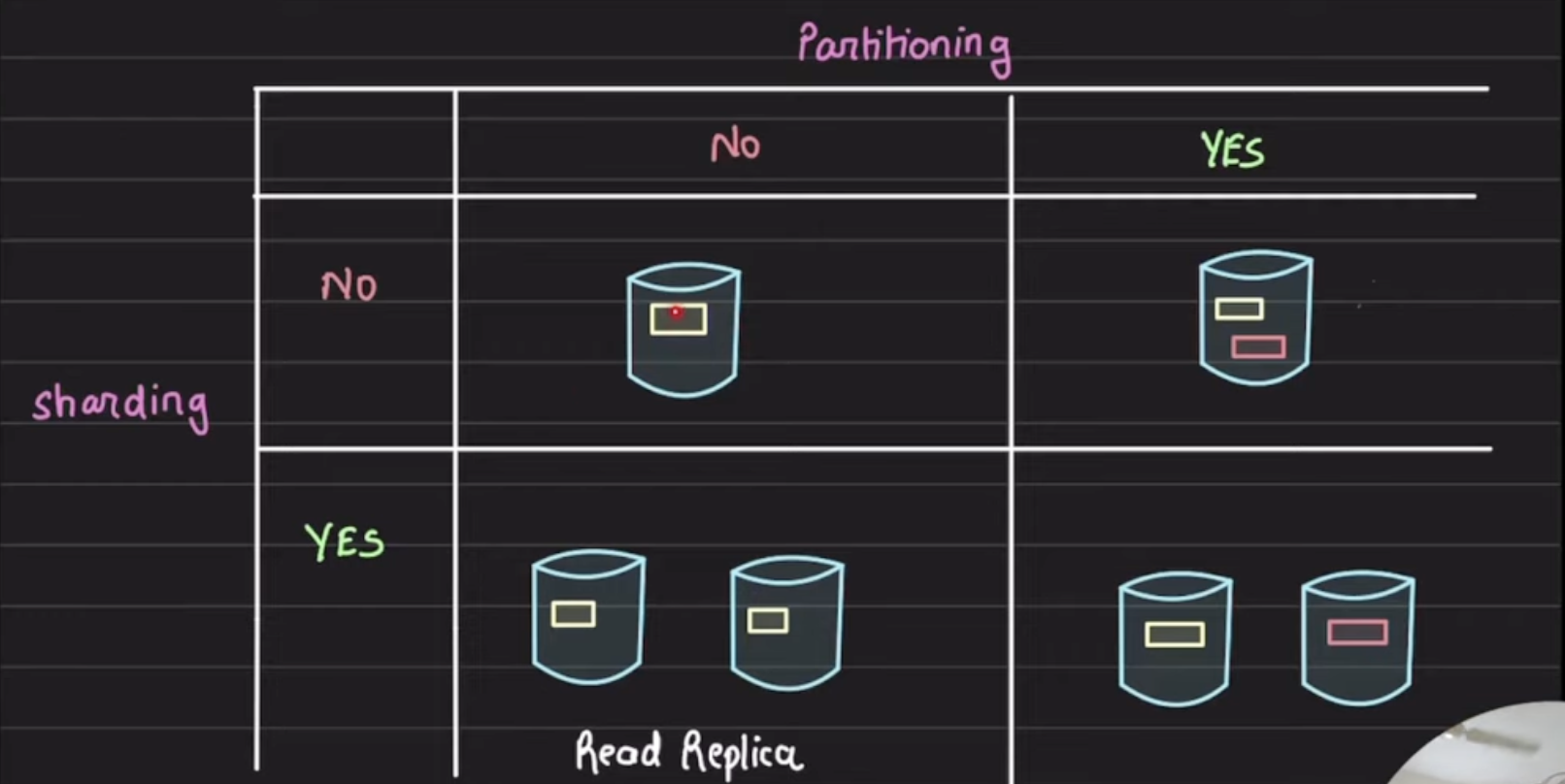
Database sharding and database partitioning are techniques used to distribute data across multiple databases or tables to improve performance, scalability, and manageability. While they share similarities, they have distinct differences and use cases. Here’s a detailed comparison.
Database Sharding:
Definition:
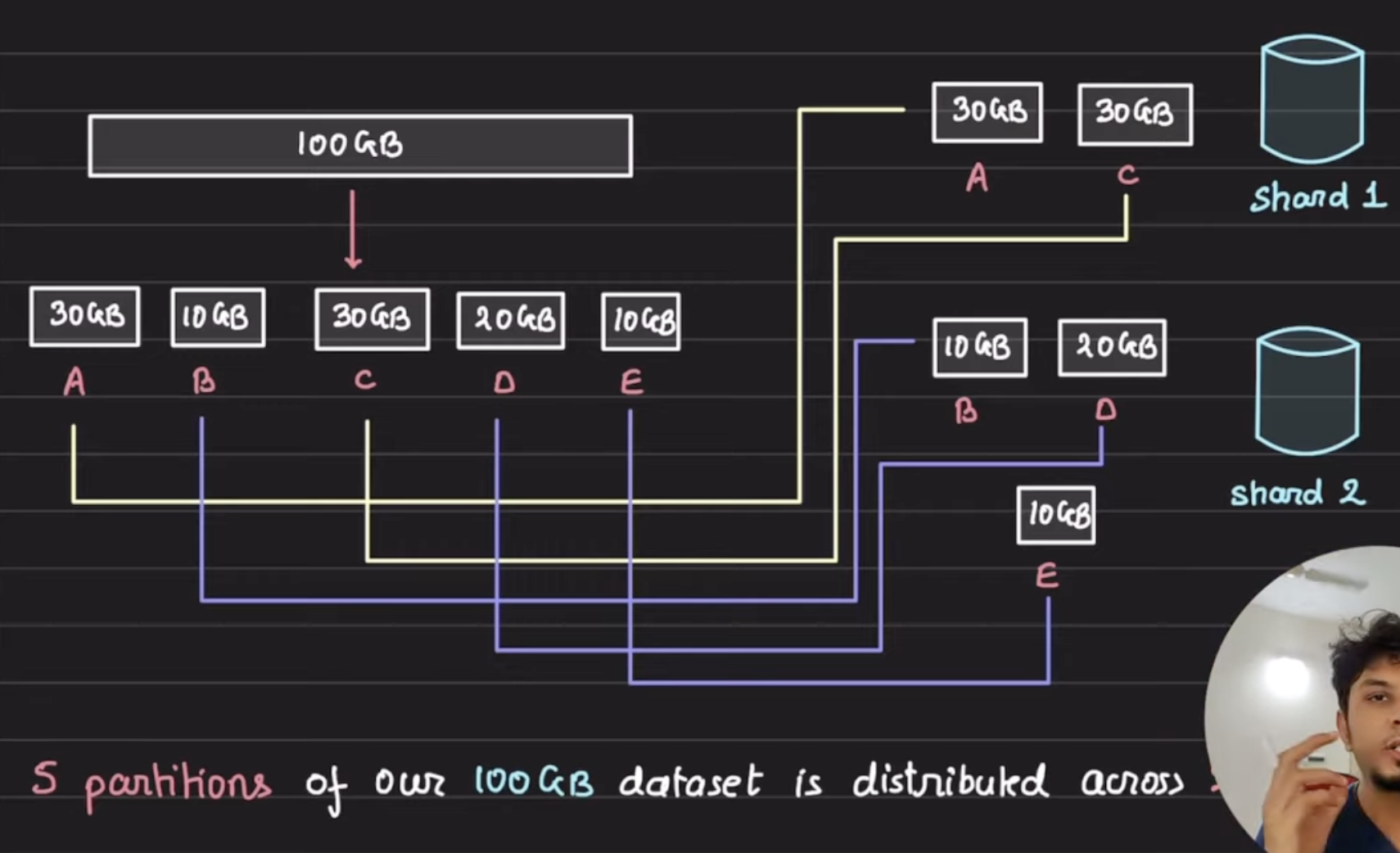
- Sharding is the process of dividing a large dataset into smaller, more manageable pieces called shards. Each shard is stored on a separate database server or cluster.
Purpose:
- It is used to scale horizontally by distributing data across multiple servers. This helps in handling large volumes of data and high transaction rates.
Implementation:
- Data is split based on a shard key, which determines the distribution of data across different shards.
- Each shard operates as an independent database with its own set of data and can be queried independently.
Characteristics:
- Shards are often distributed across different physical machines.
- Each shard contains a subset of the total data, ensuring no duplication across shards.
- Requires a mechanism to route queries to the appropriate shard.
Use Cases:
- Large-scale applications with high write and read throughput requirements, such as social media platforms, e-commerce websites, and SaaS applications.
- Scenarios where data needs to be distributed across multiple geographic locations to reduce latency.
Advantages:
- Improved performance by distributing load.
- Enhanced scalability by adding more shards (servers) as needed.
- Fault tolerance, as issues in one shard do not affect others.
Disadvantages:
- Increased complexity in managing and maintaining multiple databases.
- Requires careful design of the shard key to avoid data skew.
- Potentially complex query routing and aggregation logic.
Database Partitioning:
Definition:
- Partitioning is the process of dividing a single database table into smaller, more manageable pieces called partitions. Each partition is stored within the same database but as a separate table or file.
Purpose:
- It is used to improve performance and manageability of large tables by splitting them into smaller, more manageable parts.
Implementation:
- Data is divided based on a partition key, which determines the distribution of data across different partitions.
- Partitions can be created based on various strategies such as range, list, hash, or composite.
Characteristics:
- Partitions typically reside on the same database server or cluster.
- All partitions are part of the same database schema.
- Queries can be optimized to target specific partitions, reducing the amount of data scanned.
Use Cases:
- Databases with very large tables where querying and managing data becomes inefficient.
- Scenarios requiring efficient access to specific subsets of data, such as time-series data, regional data, or categorical data.
Advantages:
- Improved query performance by reducing the amount of data scanned.
- Easier management of large tables by operating on partitions independently.
- Enhanced maintenance tasks such as backup, restore, and archiving on a per-partition basis.
Disadvantages:
- Limited scalability compared to sharding, as partitions usually reside on the same server.
- Potential complexity in partition management and maintenance.
- Requires careful design of the partition key to ensure even data distribution.
Type of partitioning:
- Horizontal
- Vertical
Comparison Table:
| Feature | Database Sharding | Database Partitioning |
|---|---|---|
| Definition | Dividing data across multiple databases or clusters | Dividing a single table into smaller pieces |
| Purpose | Horizontal scaling, high throughput, geographic distribution | Improved performance and manageability of large tables |
| Implementation | Based on a shard key, data distributed across shards | Based on a partition key, data divided into partitions |
| Distribution | Different physical machines | Same database server |
| Complexity | Higher, requires query routing and shard management | Lower, managed within the same database |
| Scalability | High, add more shards as needed | Moderate, limited to server capacity |
| Use Cases | Large-scale applications, high read/write throughput | Large tables, time-series data, regional data |
| Advantages | Performance, scalability, fault tolerance | Query performance, maintenance, manageability |
| Disadvantages | Complexity, shard key design, query routing | Limited scalability, partition management complexity |
- Sharding is best suited for large-scale applications requiring horizontal scalability and high throughput by distributing data across multiple servers.
- Partitioning is ideal
Type of DB sharding strategies
