***Log structured Merge Tree
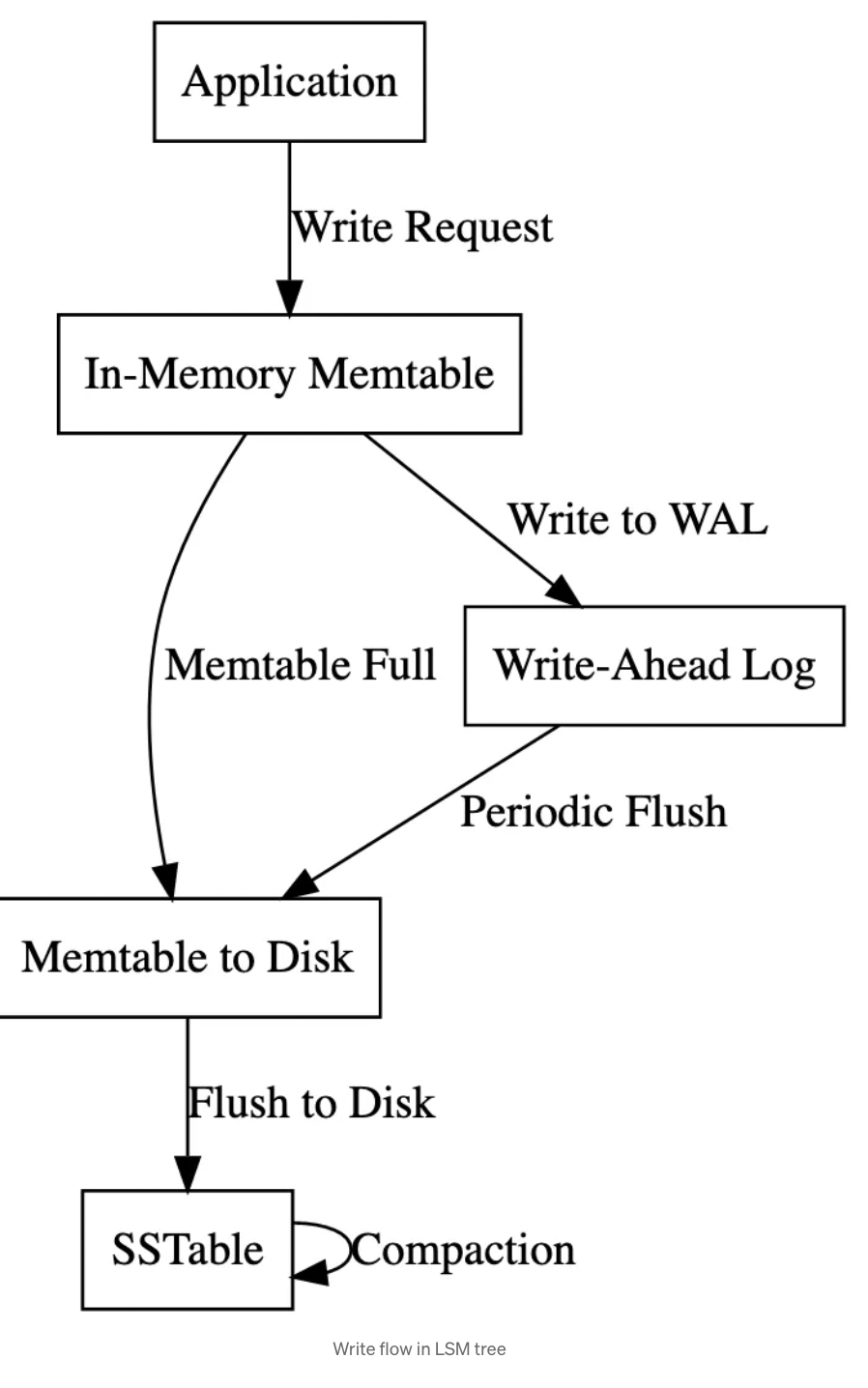
_algorithm design that helps us store massive amounts of data without making us wait forever to write it. It stores data in memory first, which is lightning fast. But since we can’t keep everything in memory, the LSM Tree periodically flushes data to disk.
It organizes the data into layers of sorted structures, each with more and more compressed data. The top layer is the fastest to access but the least compressed. As the data piles up, it’s compressed and written into a new layer called an SSTable. We can decide how many layers we need and how much compression to apply, based on the type of data we’re dealing with.
before the data is flushed to disk and organized into SSTables, it is also written to the Write-Ahead Log
How is data read from LSM tree?
- The first place the LSM tree checks is the in-memory layer
- if the data you’re searching for is not in the in-memory layer, next step is to search in disk space called SS Table.
- LSM tree uses bloom filter to check if data exist in SS table instead of search all SS tables in sequence.if the bloom filter confidently declares that the data definitely doesn’t exist in a particular SSTable, the LSM tree skips that SSTable and moves on to the next one
Use cases of LSM Trees
NoSQL databases: These databases are designed to handle large amounts of unstructured or semi-structured data, and the LSM tree architecture aligns perfectly with their requirements. LSM trees offer excellent write performance, which is crucial for managing the high data ingestion rates typically encountered in NoSQL databases.
Time series databases: Time series data is characterised by its timestamped nature, where data points are associated with specific time intervals. LSM trees provide efficient storage and retrieval of time series data, thanks to their sorted structure.
Search engines: Search engines need to index and retrieve vast amounts of data quickly to provide relevant search results. LSM trees, with their ability to handle large datasets and provide efficient read operations, are a natural fit for search engine architectures.
Log systems: In log systems, data needs to be written in an append-only manner, preserving the order of events. LSM trees excel in this scenario, as they offer efficient write operations by sequentially appending new data to the in-memory layer.