User table
| id | name | age | bio | total_blogs |
|---|---|---|---|---|
| 4B | 60 B | 4B | 128B | 4B |
| 1 | anju | 32 | nasdjns | aadjasnjk |
| 1 row 200B | ||||
| let 100 rows, total size = 200 * 100 B |
How read happens:
one disk read = one block read of sample size 600B 1 GB hard disk is split into 600B size blocks 1 read will load complete block which contains that data.
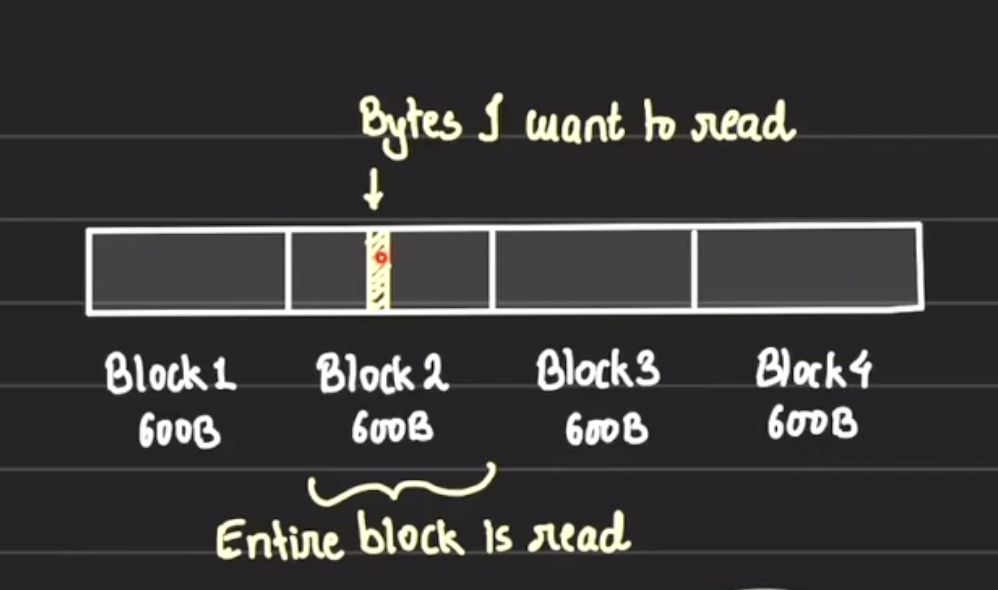
Each record is 200B, Block size= 600B, total 100 records Each block can hold 3 record. 100/3 = 33.33 = 34 blocks will be needed to store 100 records.
assume 1 sec to read one block so total 34 sec will be needed to read all the records i.e 34 blocks
Example query without index:
Select User where age>23 steps involved: iterate table row by row i.e block by block read block in memory check if age>23 in each record of that block if yes, add record to output buffer if no, discard that row return the output buffer
Time taken: Time taken to read all the blocks 34 Sec
With Index:
user_age_index
| age(4B) | rowId(4B) |
|---|---|
| 21 | 2 |
| 22 | 3 |
| 22 | 5 |
| 23 | 1 |
| 23 | 4 |
| 24 | 6 |
Total index size: 4+4 = 8 * 100 = 800B 600B for 1 block 2 blocks needed for complete index
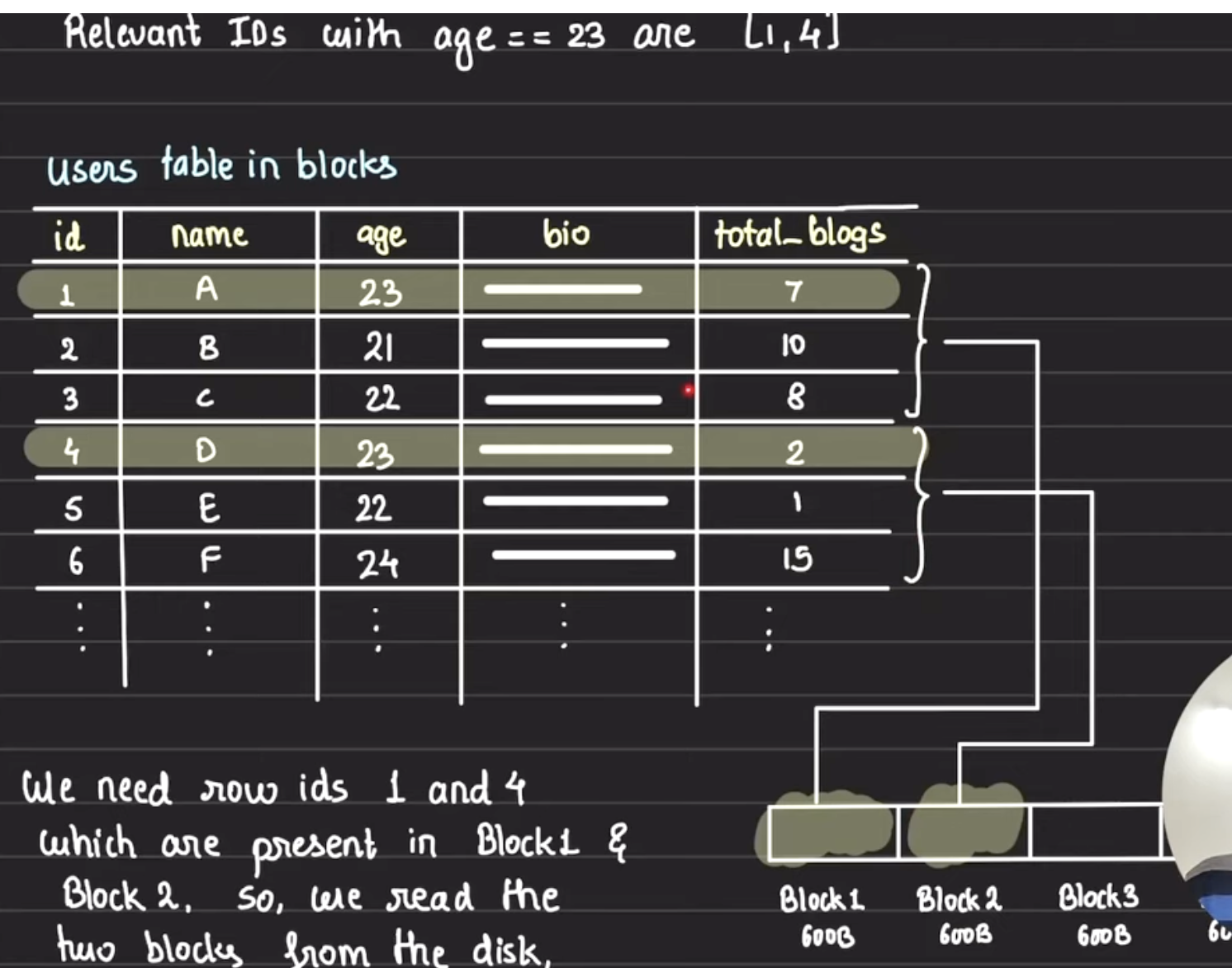
Steps involved:
Iterate index (worst case complete index block by block) Check if entry has age>23 If yes add id in buffer If no discard For all id from the buffer read all id from disk add it to buffer return buffer
for this data, we only need to read 4(2 for index, 2 for data) block instead of 34 blocks. so it will take 4 sec.
Think about big size data
Indexing on distributed database
Example: blog database
| id | author | category | title | body |
|---|---|---|---|---|
| 1 | u1 | mysql | title1 | body1 |
| 9 | u2 | go | title | body |
| 8 | u3 | ngnix | title | body |
| 7 | u3 | mysql | title | body |
index on author
data is stored in 2 shards, and sharded based on authorId

if we have to fetch all books with category mysql select * from blogs where category = “mysql” it will need to fanout query on all the shards and scan complete DB. if any of the shard is slow, it will wait for all the shards to respond.
To solve this issue GSI Global Secondary Indexes comes into picture. Create Global index for these kinds of data patterns. Data will be partitioned based on the category attribute of the blog. Some DB like dynamo already provide this feature
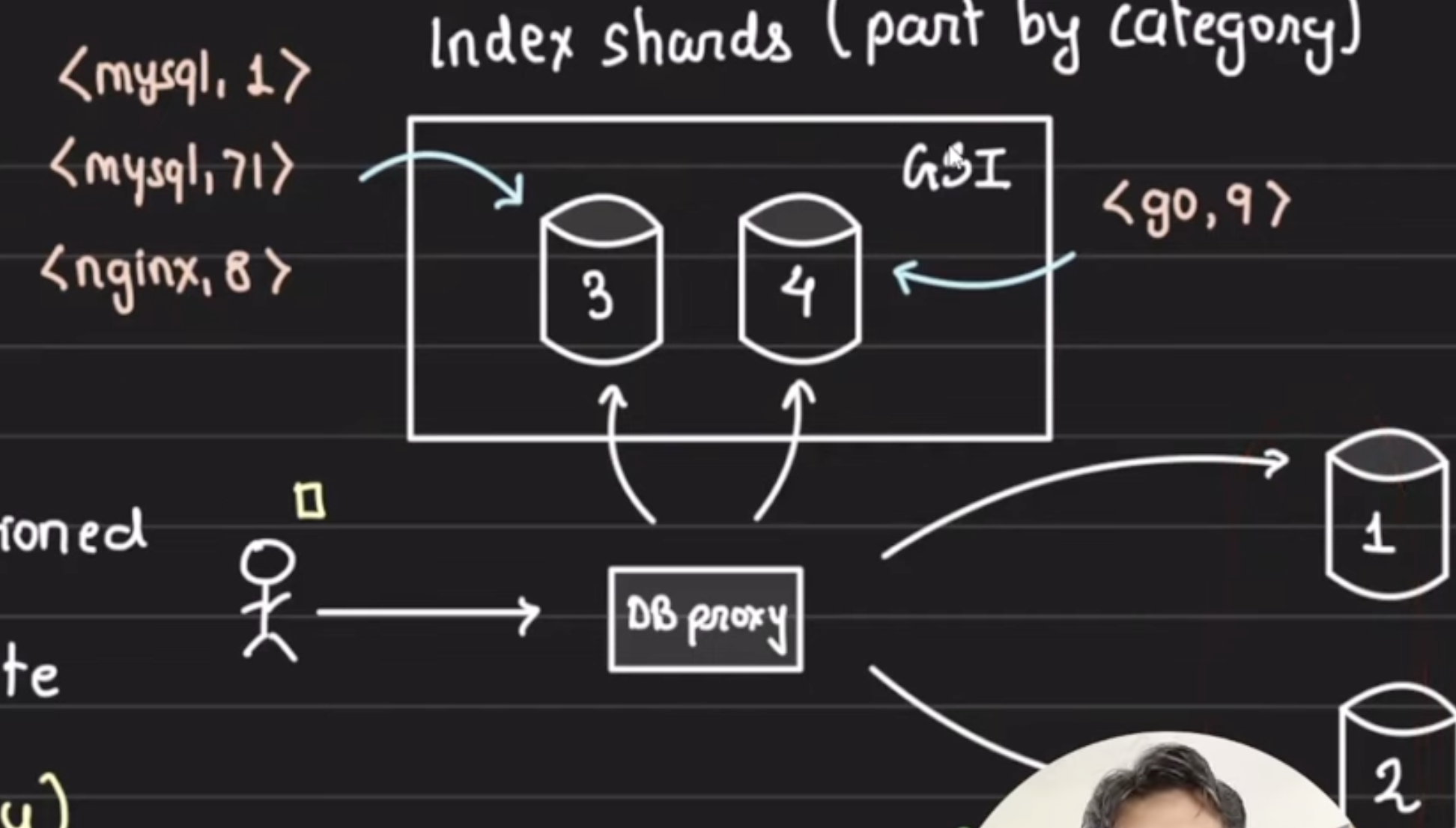
There should be limit on GSI, else write operation will become too heavy
If your query pattern is designed to fetch all data belonging to given category for given Author.
Data is shared based on authorId. here partition key is present in query where clause.
We can create LSI local secondary index, this index data will be stored on that particular shard which will store data on the node keeping data of that author.
instead of fanning out query on all the shard it will go to particular shard, fetch row detail from LSI and then fetch actual record.
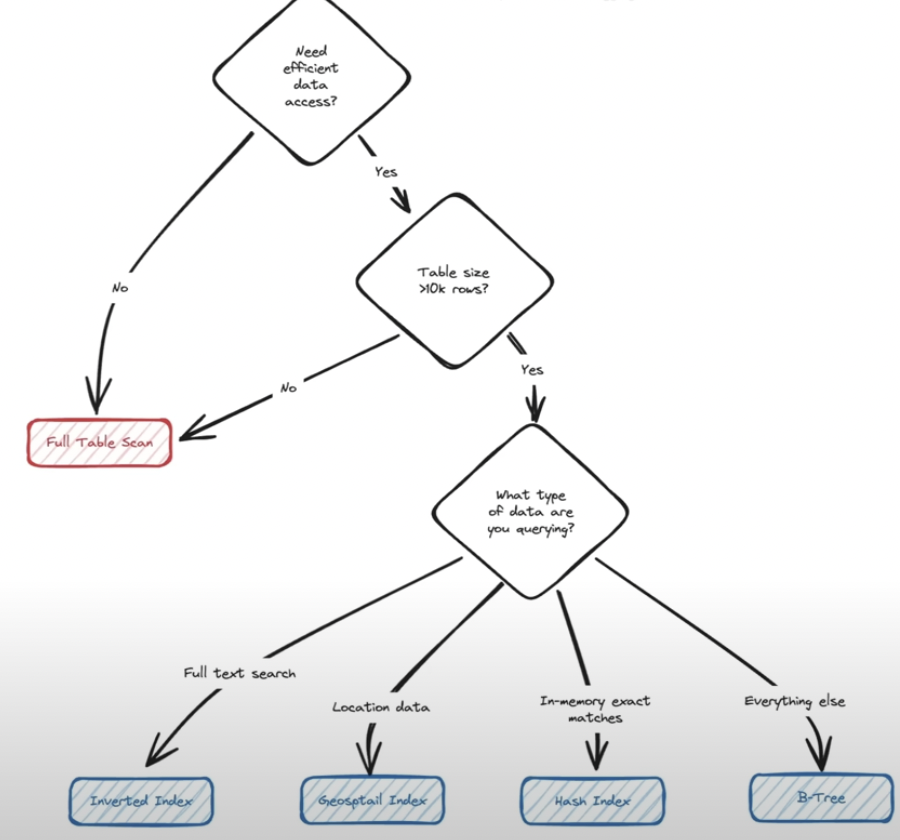
Different type of index:
Hash Index:
It is majorly used for caching database
BTree:
B-tree indexes are the most common type of database index, providing an efficient way to organize data for fast searches and updates. They achieve this by maintaining a balanced tree structure that minimizes the number of disk reads needed to find any piece of data.
It provides indexing on 1 D data.
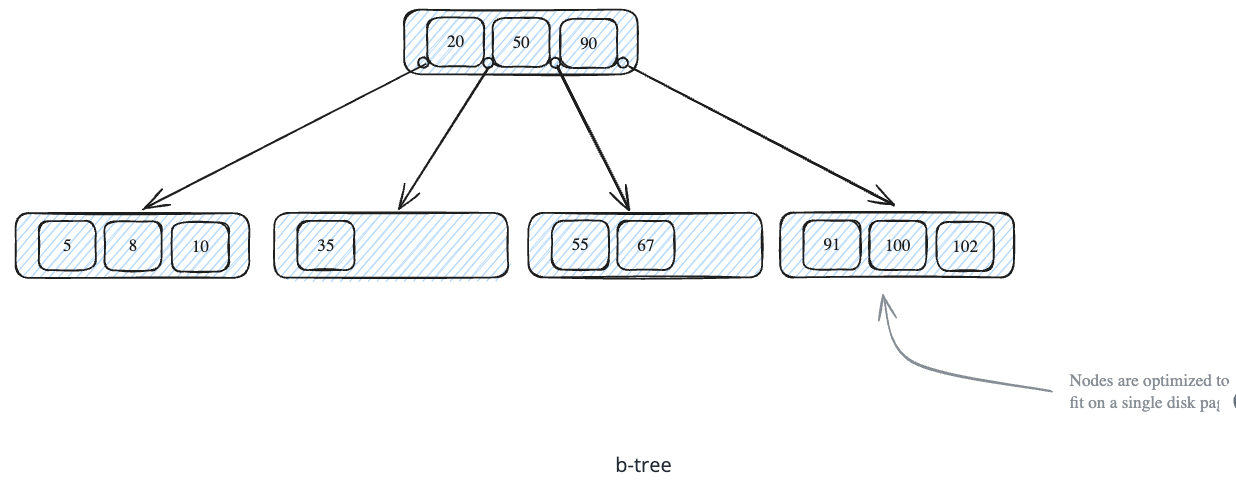
Why to use B Tree:
- It maintains data in sorted order, and optimise range queries.
- It is self balancing, new random addition and removal does well in terms of performance.
- It minimize disk IO by matching their structure with DB. i.e keeping index sorted and arrange in sequence
Geospatial Index:
2D data
Ex: select * from location where lat> 100 and lat<400 and long> 50 and long<200;
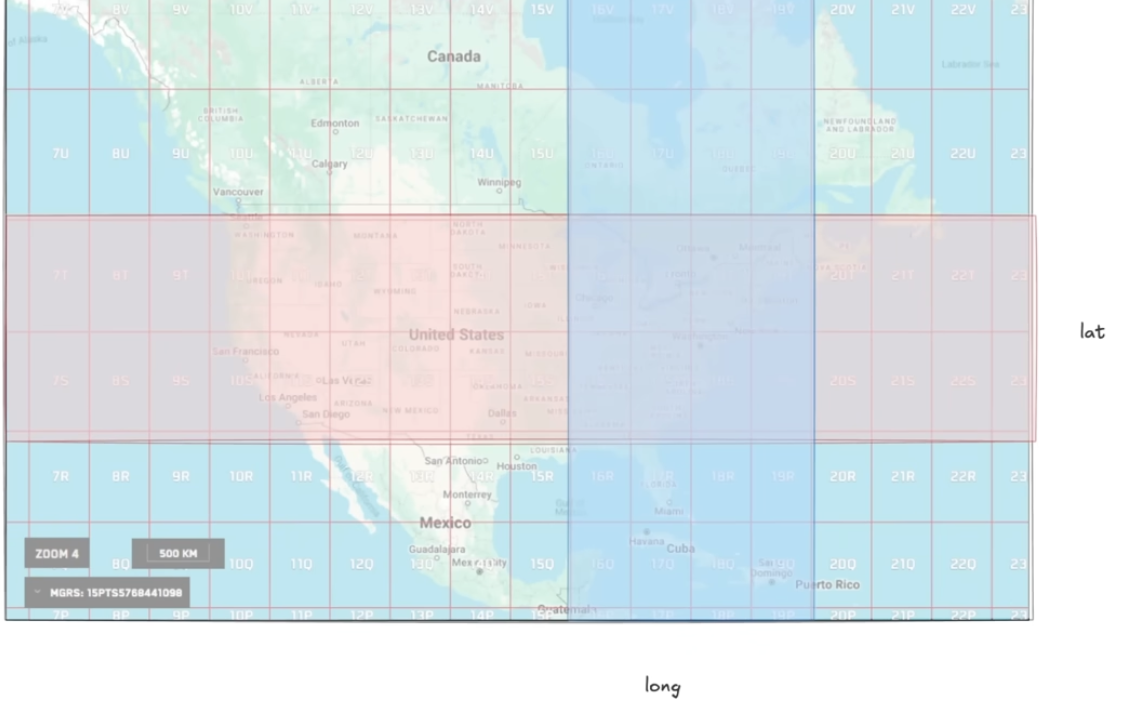
result are created after merging pink and blue lat and long area using different type of algorithms.
Geo hasing Algorithm`
Converts 2D cordinates into 1D numbers
`Used in : Redis
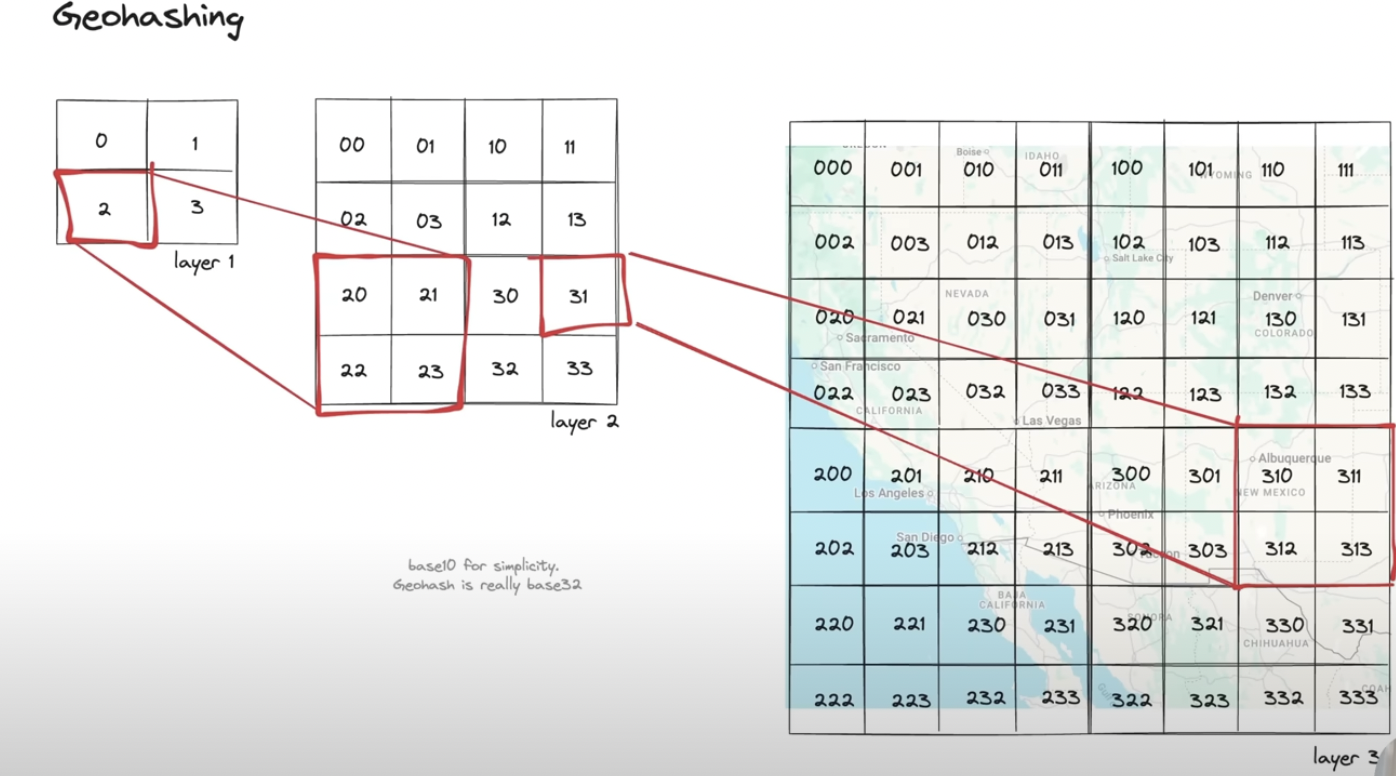
This maps smaller area inside larger area with common prefixes.
Ex: state has code 2, district will be 21,22,23,24 then city inside district 22 will be 221,222,223,224
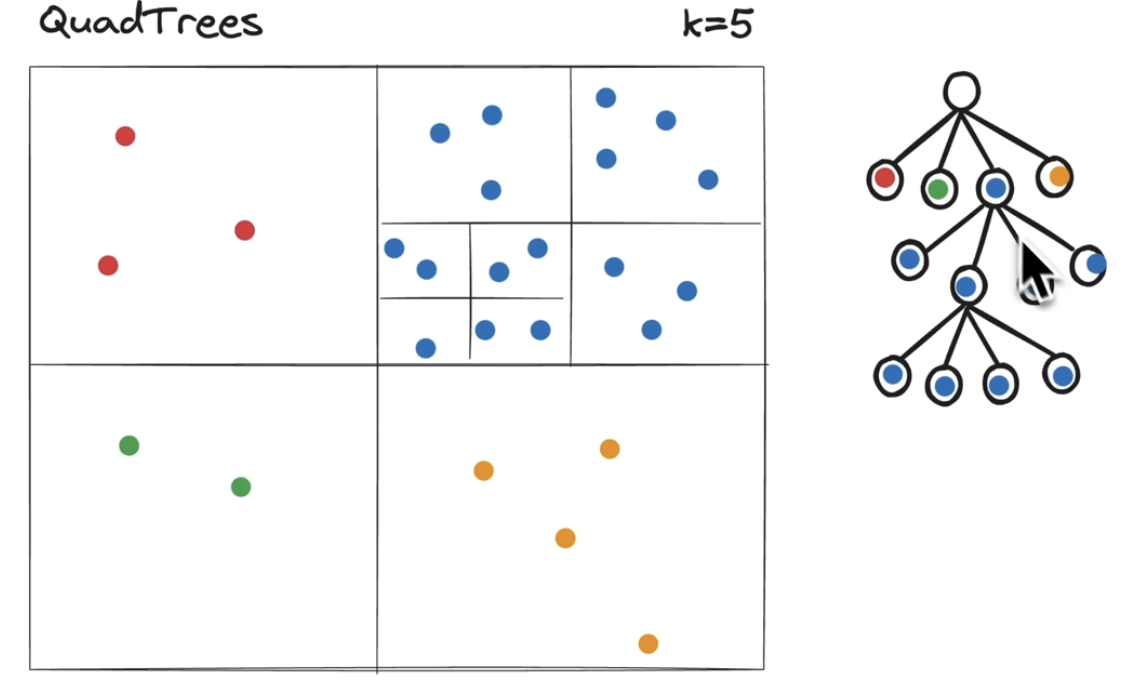
Quadtrees
This also Split the word recursively into K dimension. If parent has more than K node, split it further
Difference from Geo Hashing is its not 1 dimensional number set. its a tree structure and expend child only when there is more density area present for parent node.
R Tree
Inverted index
`used in elastic search, postgres full text search
Strings are lexicographically sorted.
Inverted index are data structure designed to optimise queries based on prefix search or string matching in group of documents.
Ex: Select * from document where name like ‘%fast%‘;
Doc1: “B-tree are fast and reliable” doc2: “B-tree are fast but limited” doc3: “B tree handle range query faster”
Inverted Index: B-tree - > {doc1, doc2, doc3} fast → {doc1, doc2}
Type of index and uses