In memory data structure, Single threaded open source cache written in ‘C’.
Data structure:
Hash, List, Set, sorted set(priority queues), bitmap, hyperlog log, geospatial index, streams, timeseries
Application can be supported: Gaming leaderboard message buffer auth session store realtime analytics
`Redis can be configurated to expects all the data for a given request to be on a single node!Choosing how to structure your keys is how you scale Redis.
_How much data redis single node can store:
- Available Physical Memory (RAM) on the server where Redis is running.
- Redis Internal Data Structure Overheads, which vary depending on the data types and structures used. -For most 64-bit systems, Redis can address up to 4 terabytes (TB) of RAM, as long as the system itself supports that much physical memory.
Advantages:
Fast Read and write
Redis can handle O(100k) writes per second and read latency is often in the microsecond range
Single Command on Redis is atomic:
if one command is running, no other command can be executed in between. Concurrency is not an issue for redis. and also there is no context switch as only single atomic command is executed.
Data is stored as in memory:
It also provide configurable persistence storage in memory
Command executed is saved in log files always
Transition
Pub/Sub
TTL
LRU eviction
How Redis maintains these many connection??
I/O multiplexing
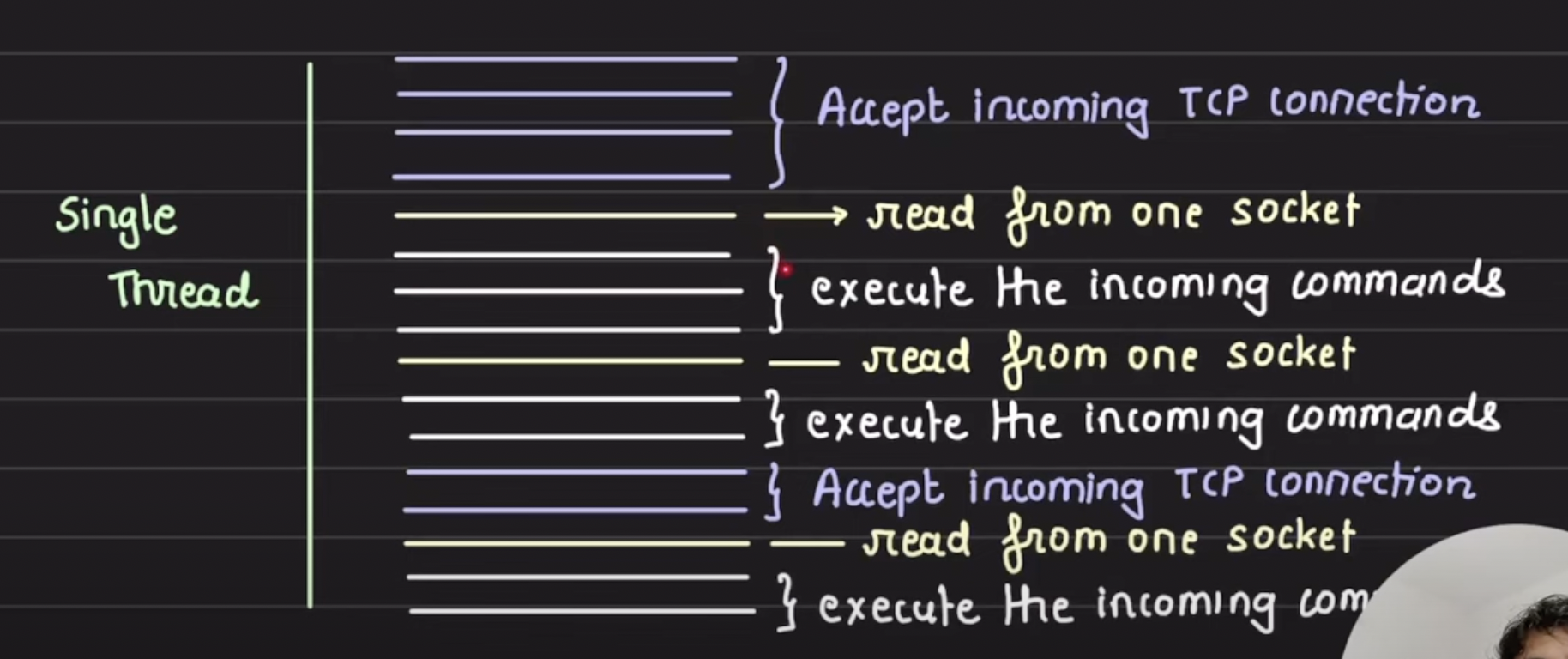
Redis need to perform 2 actions:
- Read from TCP connections
- Perform in memory operations for the commands received over TCP connections.
Redis takes advantage of read system calls and listen to only TCP socket connection which has some data to be read. this way it is able to maintain too many connections.
Also Redis perform in memory operations too quick because redis keeps data in memory, with the single thread redis is able to perform quick action using advantage of in memeory and read only when data available feature
Capabilities and Uses cases of Redis
Redis as a Cache
Redis as a Distributed Lock
A very simple distributed lock with a timeout might use the atomic increment (INCR) with a TTL. When we want to try to acquire the lock, we run INCR. If the response is 1 (i.e. we own the lock), we proceed. If the response is > 1 (i.e. someone else has the lock), we wait and retry again later. When we’re done with the lock, we can DEL the key so that other proceesses can make use of it.
Redis for Leaderboards
Redis’ sorted sets maintain ordered data which can be queried in log time which make them appropriate for leaderboard applications. Each element (member) in a sorted set has a unique identifier (e.g., a post ID) and an associated numeric score (e.g., number of likes). The set is always ordered from the lowest to the highest score.
ZADD mostLikedPosts 100 post1
ZADD mostLikedPosts 150 post2
ZADD mostLikedPosts 80 post3
ZREMRANGEBYRANK mostLikedPosts 0 -10 # Remove all but the top 10 posts
- In this example, `post2` is the most liked post, followed by `post1`, then `post3`.
-
ZINCRBY mostLikedPosts 1 post1 //This command increases `post1`'s score by 1. If multiple users like a post concurrently, Redis handles these increments atomically, ensuring data consistency.
ZREVRANGE mostLikedPosts 0 9 WITHSCORES // retrun most liked top 10 post with score
Redis provides the ZINCRBY command, which allows you to increment the score of a member atomically. This is perfect for scenarios like liking a post.
Redis for Rate Limiting API Requests)
Fixed-window rate limiter where we guarantee that the number of requests does not exceed N over some fixed window of time W When a request comes in, we increment (INCR) the key for our rate limiter and check the response. If the response is greater than N, we wait. If it’s less than N, we can proceed. We call EXPIRE on our key so that after time period W, the value is reset.
Redis for Proximity Search
GEOADD key longitude latitude member # Adds “member” to the index at key “key” GEORADIUS key longitude latitude radius # Searches the index at key “key” at specified position and radius
Redis for Event Sourcing
Redis’ streams are append-only logs similar to Kafka’s topics. The basic idea behind Redis streams is that we want to durably add items to a log and then have a distributed mechanism for consuming items from these logs.
Redis solves this problem with streams (managed with commands like XADD) and consumer groups (commands like XREADGROUP and XCLAIM).
Redis Session Store:
The web server stores the user’s data and preferences.
Yet it’s hard to scale a stateful web server.
So they installed a separate session store using Redis.
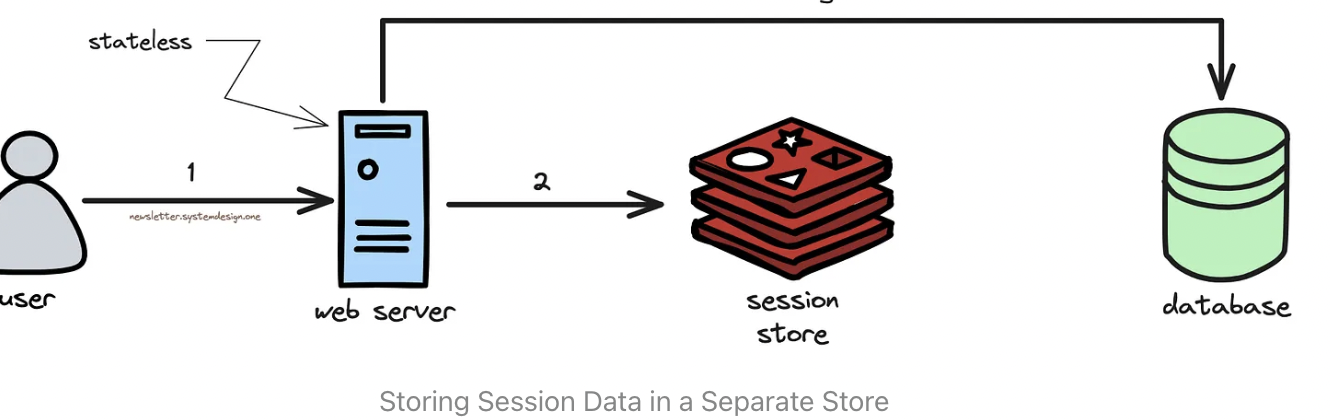
Storing Session Data in a Separate Store
How it works:
- Session data is stored in the Redis hash data structure
- An expiry time is set for each user’s data
- The expiry time gets renewed whenever the user requests something It let them
- Scale stateless web servers easily
- Handle traffic spikes
Redis rs Memcache
Memcache
- uses consistent hasing to provide dynamic partitioning support
- Multithreaded
- Uses LRU eviction can be archived by linkedHashMap and Hashmap
- Multileader/leader less
- More flexible less convinence
Redis
- Single threaded help in achieving ACID properties
- No variable partitioning
- write ahead log, allows us to do atomic transactions
- Single leader application
The **Redis Sorted Set(priorty queue) **: keep data sorted based on some parameter. Redis’ sorted sets maintain ordered data which can be queried in log time which make them appropriate for leaderboard applications. The high write throughput and low read latency make this especially useful for scaled applications where something like a SQL DB will start to struggle.