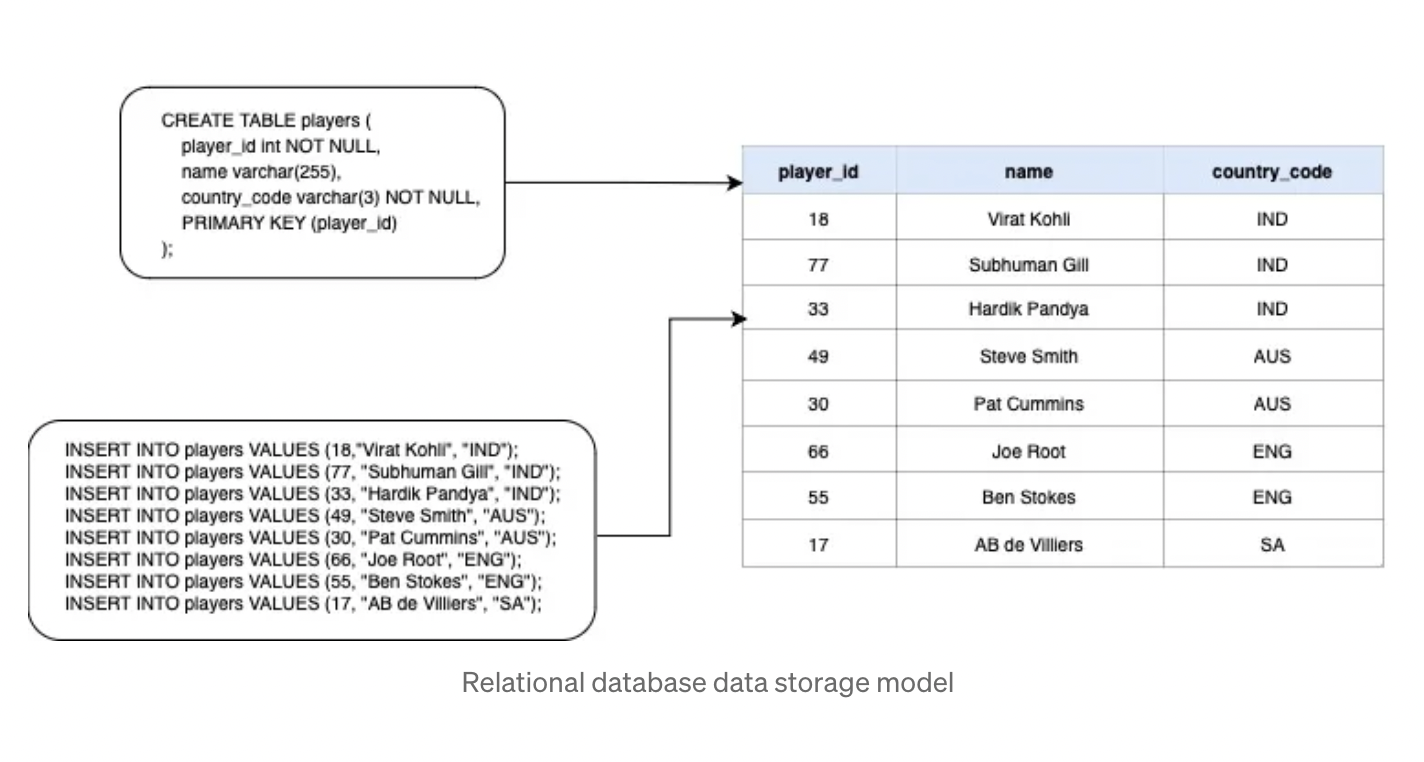
Apache Cassandra is a highly scalable and distributed NoSQL database which can handle large amounts of data across multiple nodes and data centers.
Cassandra is a wide-column store NoSQL database, in which unlike relational databases, data is stored in a column-family format, which means each row has a unique key while column name and format can vary across rows.
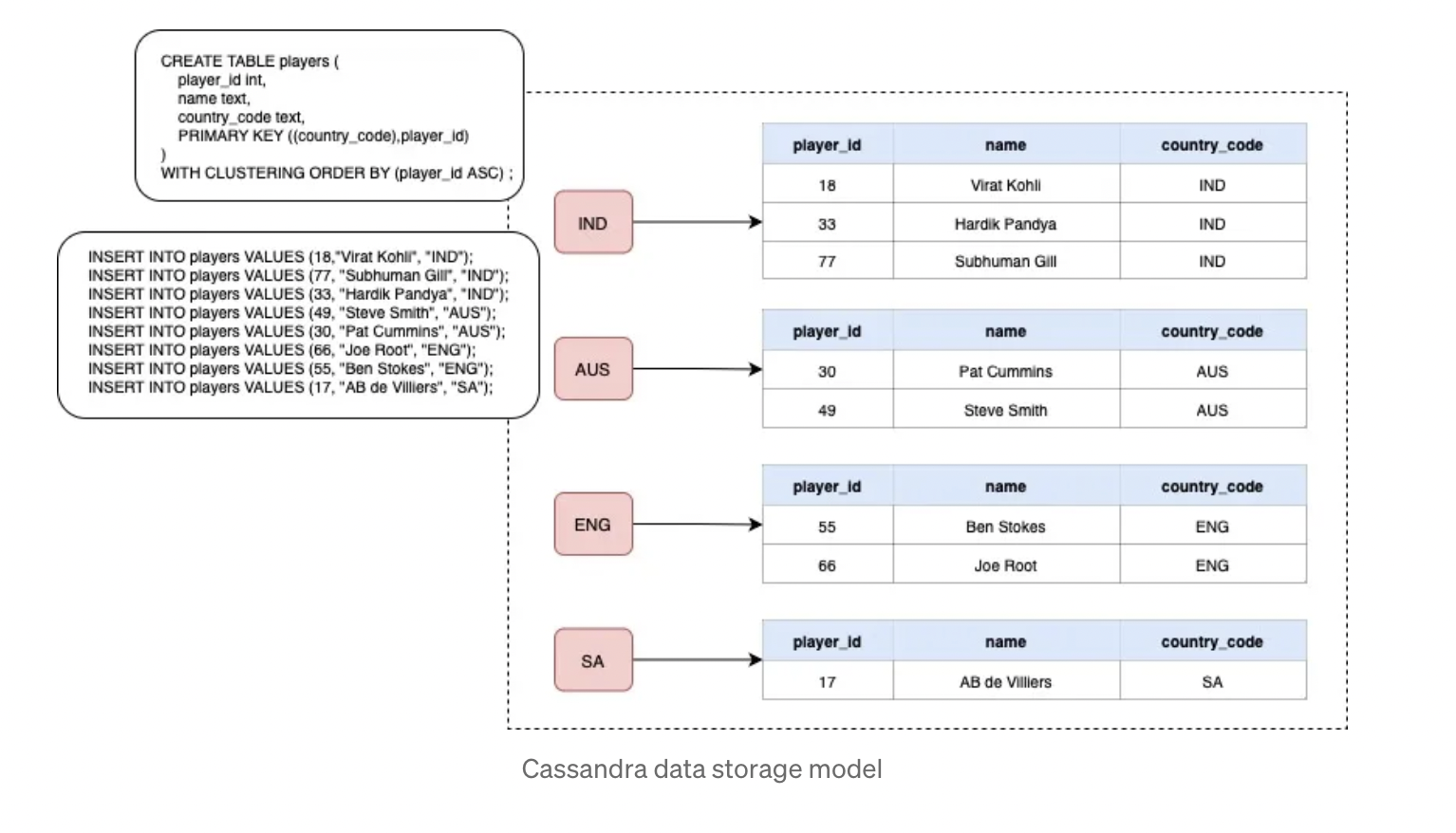
Primary key of Cassandra is combination of partition key and clustering key
Create table Player{
playerId, //clustering key(sortKey)
name,
countryId // partition key
PRIMARY_KEY((countryId), playerId)
}
- Partitioner uses a consistent hashing algorithm to convert this key into tokens which is then used to determine where the data will reside on the ring(cluster of nodes). This is the reason why querying for data in Cassandra is super-efficient, because it knows where exactly the data is going to be.
- Clustering key is the second part of primary key used to ensure uniqueness to primary key in order to avoid collision, and to sort the data inside a partition. In the above example, we can see that data is being sorted by player_id inside each partition.
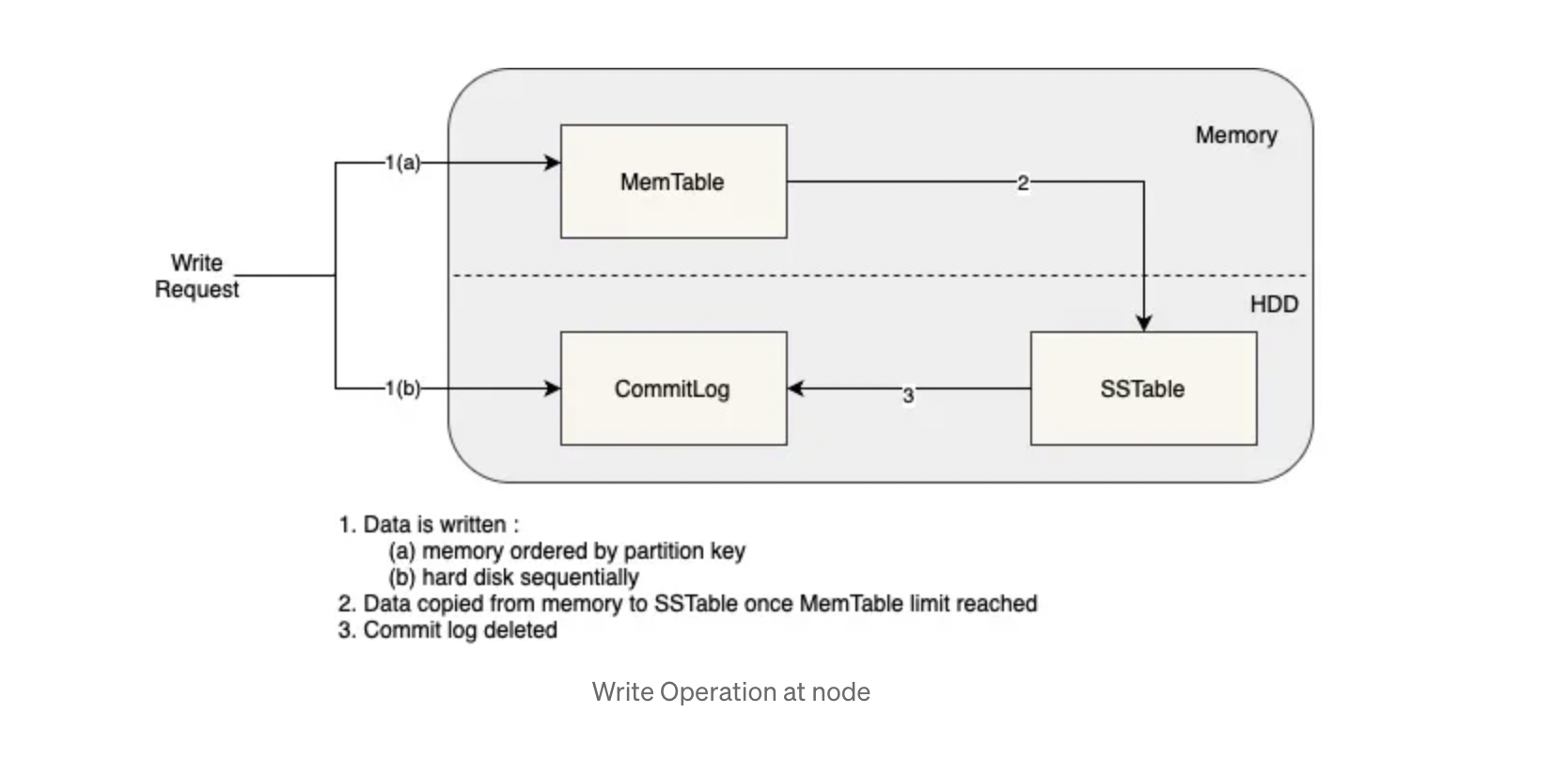
Commit Log - This basically is a write-ahead-log to ensure durability of writes for Cassandra nodes. Memtable - An in-memory, sorted data structure that stores write data. It is sorted by primary key of each row. SSTable: Immutable file on disk containing data that was flushed from a previous Memtable
To prevent bloat of SSTables with many row updates / deletions, Cassandra will run compaction to consolidate data into a smaller set of SSTables, which reflect the consolidated state of data. Compaction also removes rows that were deleted, removing the tombstones that were previously present for that row. This process is particularly efficient because all of these tables are sorted.
Why and when to use Cassandra
*#Partitioning: Cassandra achieves horizontal scalability by partitioning data across many nodes in its cluster. In order to partition data successfully, Cassandra makes use of consistent hashing.
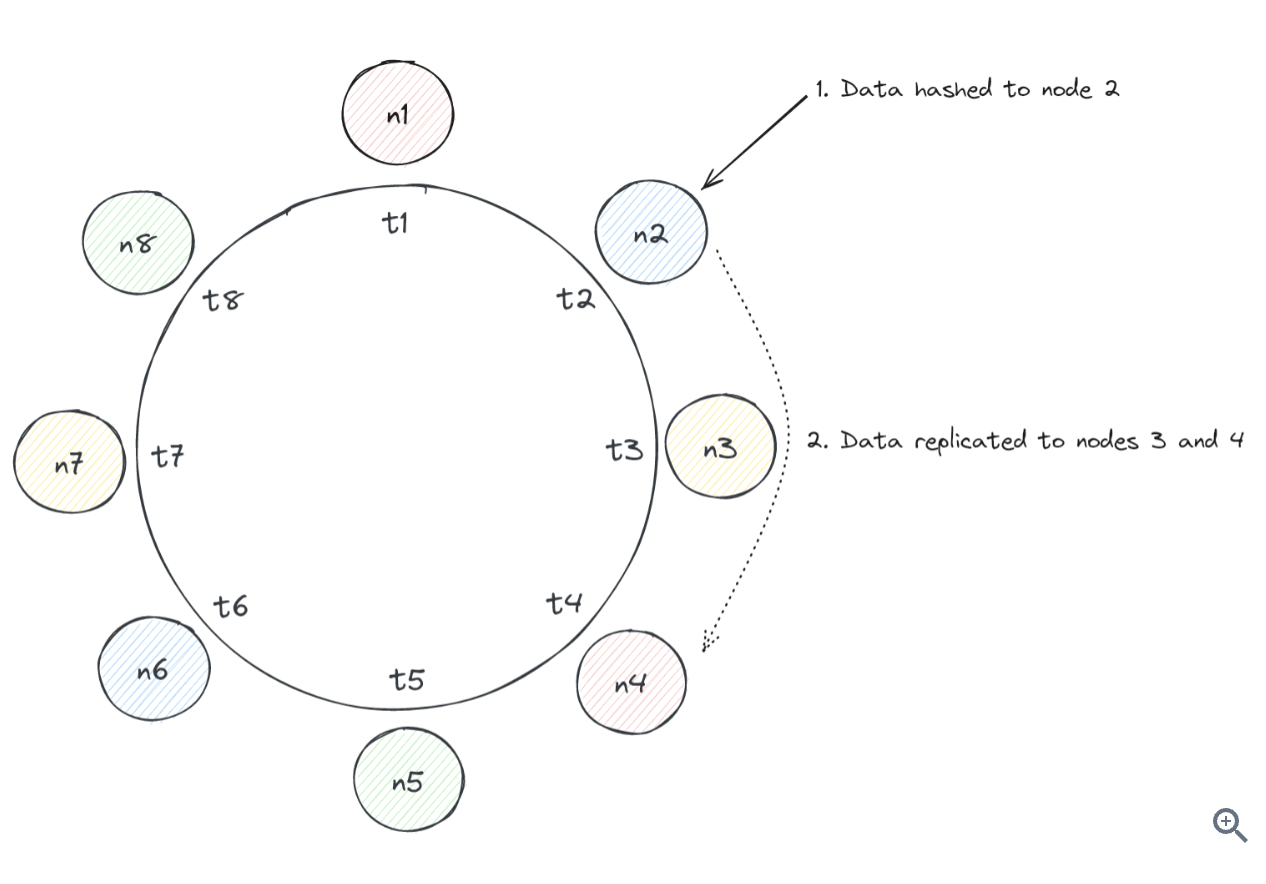
_Cassandra, partitions of data are replicated to nodes on the ring, enabling it to skew extremely available for system designs. Cassandra is trying to replicate data to 3 nodes, it will hash a value to a node and scan clockwise to find 2 additional virtual nodes to serve as replicas.
Virtual Node with same color will be on same physical node
Cassandra has two different “replication strategies” it can employ: NetworkTopologyStrategy and SimpleStrategy.
NetworkTopologyStrategy is the strategy recommended for production and is data center / rack aware so that data replicas are stored across potentially many data centers in case of an outage. It also allows for replicas to be stored on distinct racks in case a rack in a data center goes down. The main goal with this configuration is to establish enough physical separate of replicas to avoid many replicas being affected by a real world outage / incident.
*#Consistency _Cassandra gives users flexibility over consistency settings for reads / writes, which allows Cassandra users to “tune” their consistency vs. availability trade-off.
Cassandra does not offer transaction support or any notion of ACID gurantees.
*#Query Routing
_Any Cassandra node can service a query from the client application because all nodes in Cassandra can assume the role of a query “coordinator. They share cluster information via a protocol called “gossip”
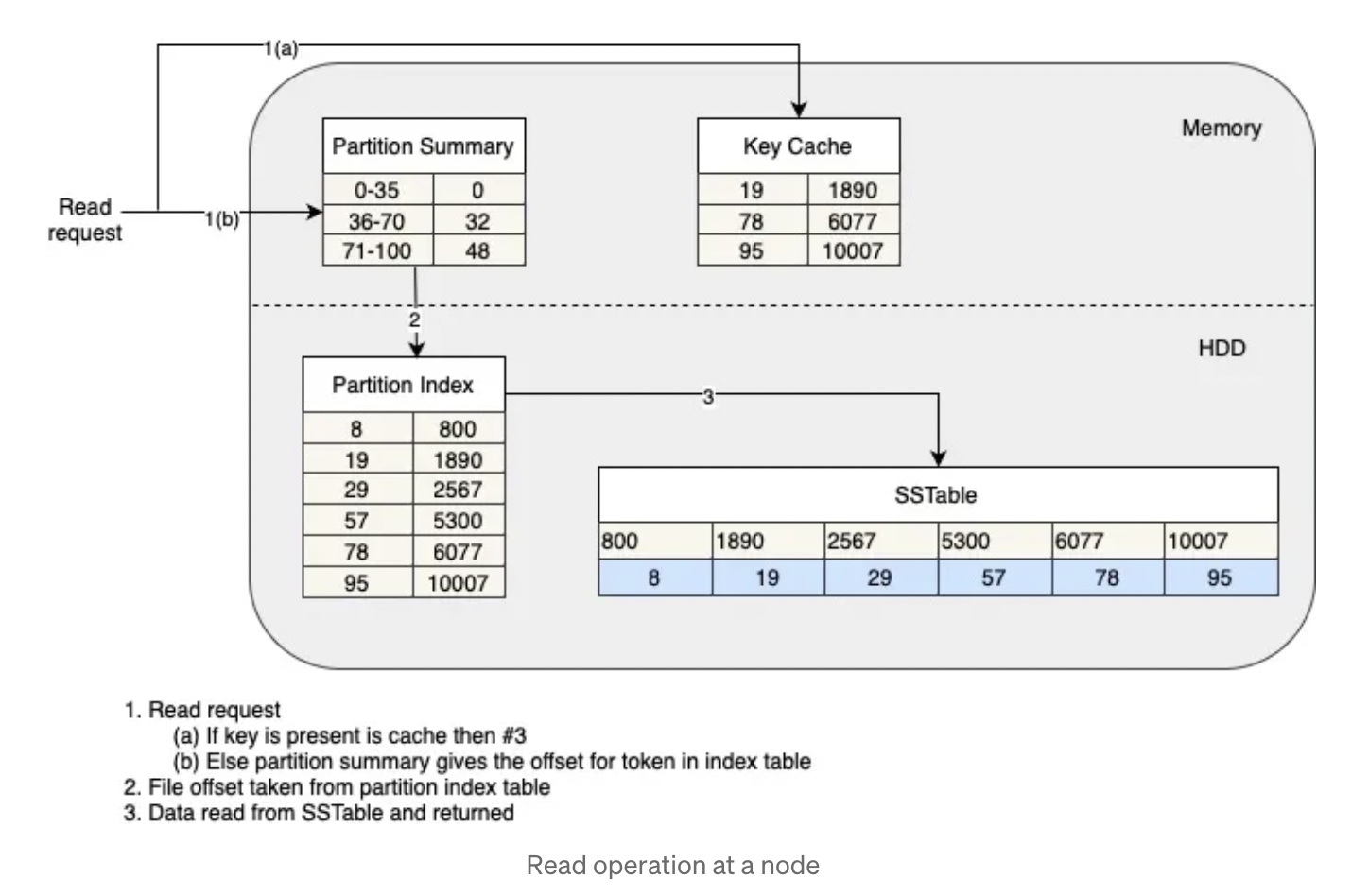
*#Storage Model Cassandra uses LSM tree to achieve speed. IT uses memtable and SSTable and bloom filter to quickly findout if data exist or not in each level of LSM tree data sets. The data in SSTables is sorted by primary key, making it easy to find a particular key. `Cassandra opts for an approach that favors write speed over read speed. Its a masterless peer to peer communication cluster
*_Cassandra is best suited for chats applications like discord Discord channels can be quite busy with messages. Users typically query recent data given the fact that a channel is basically a big group chat. Users might query recent data and scroll a little bit, so having the data sorted in reverse chronological order makes sense.
CREATE TABLE messages (
channel_id bigint, `message_id bigint, `author_id bigint, `content text, `PRIMARY KEY (channel_id, message_id) `` `) `WITH CLUSTERING ORDER BY (message_id DESC);
__You might wonder why message_id is used instead of a timestamp column like created_at? Discord opted to eliminate the possibility of Cassandra primary key conflicts by assigning messages i.e A Snowflake ID is basically a chronologically sortable UUID. This is preferable to created_at because a Snowflake ID collision is impossible (it’s a UUID), wheras a timestamp, even with millisecond granularity, has a likelihood of collision.
The above schema enables Cassandra to service messages for a channel via a single partition. The partition key, channel_id, ensures that a single partition is responsible for servicing the query, preventing the need to do a “scatter-gather” query across several nodes to get message data for a channel, which could be slow / resource intensive. Some Discord channels can sometimes have an extremely high volume of messages. With the above schema, Discord noticed that Cassandra was struggling to handle _large partitions corresponding to busy Discord channels.
To solve the large partition problem, Discord introduced the concept of a bucket and add it to the partition key part of the Cassandra primary key. A bucket represented 10 days of data.The messages of even the most busy Discord channels over 10 days would certainly fit in a partition in Cassandra. over time, a new partition would be introduced because a new bucket would be created.
CREATE TABLE messages (
channel_id bigint, bucket int,
message_id bigint, author_id bigint,
content text, PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
Advanced Features
****Storage Attached Indexes (SAI)**: Offer global secondary indexes on columns. These enable Cassandra users to avoid excess denormalizing of data if there’s query patterns that are less frequent. Lower frequency queries typically don’t warrant the overhead of a separate, denormalized table for data.
**Materialized Views: Materialized views are a way for a user to configure Cassandra to materialize tables based off a source table.
Why write/read is fast?
Commit Log:By writing to a commit log on the local node before the memtable, Cassandra ensures that writes are durable, even if the node crashes before the data is written to the memtable. This reduces the latency of write operations.Asynchronous Writes:Cassandra uses an asynchronous write model, meaning that write requests are acknowledged as soon as they are written to the commit log, rather than waiting for them to be written to the memtable or sstables. This allows for write operations to be acknowledged quickly, reducing the latency of write operations.Compaction:By compacting sstables, Cassandra reduces the amount of disk I/O required for write operations, further improving write performance.Read via bloomfilter and memtable
Cassandra for Ticket master section details: TicketMaster