•The query throughput increases, so you want to add more CPUs to handle the load. • The dataset size increases, so you want to add more disks and RAM to store it. • A machine fails, and other machines need to take over the failed machine’s responsibilities. All of these changes call for data and requests to be moved from one node to another.
The process of moving load from one node in the cluster to another is called rebalancing.
rebalancing is usually expected to meet some minimum requirements: • After rebalancing, the load (data storage, read and write requests) should be shared fairly between the nodes in the cluster. • While rebalancing is happening, the database should continue accepting reads and writes. • No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load.
- hash mod N The problem with the mod N approach is that if the number of nodes N changes, most of the keys will need to be moved from one node to another. For example, say hash(key) = 123456. If you initially have 10 nodes, that key starts out on node 6 (because 123456 mod 10 = 6). When you grow to 11 nodes, the key needs to move to node 3 (123456 mod 11 = 3), and when you grow to 12 nodes, it needs to move to node 0 (123456 mod 12 = 0). Such frequent moves make rebalancing excessively expensive. We need an approach that doesn’t move data around more than necessary.
- Fixed number of partitions:
create many more partitions than there are nodes, and assign several partitions to each node.
Now, if a node is added to the cluster, the new node can steal a few partitions from every existing node until partitions are fairly distributed once again.If a node is removed from the cluster, the same happens in reverse.
.
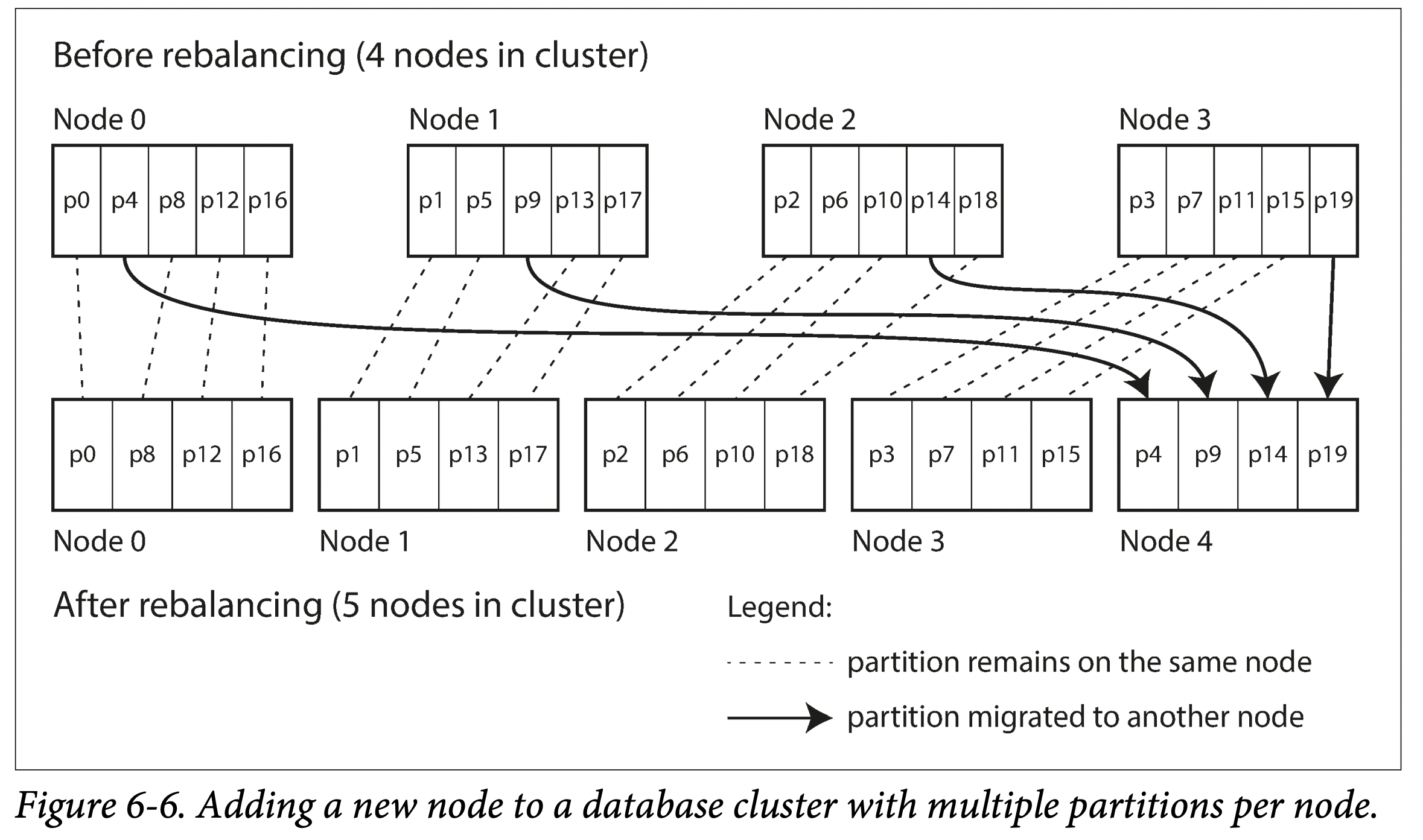
This approach to rebalancing is used in Riak, Elasticsearch, Couchbase , and Voldemort. The best performance is achieved when the size of partitions is “just right,” neither too big nor too small, which can be hard to achieve if the number of partitions is fixed but the dataset size varies.
- Dynamic partitioning key range–partitioned databases such as HBase and RethinkDB cre‐ ate partitions dynamically. When a partition grows to exceed a configured size (on HBase, the default is 10 GB), it is split into two partitions so that approximately half of the data ends up on each side of the split. Conversely, if lots of data is deleted and a partition shrinks below some threshold, it can be merged with an adjacent par‐ tition. This process is similar to what happens at the top level of a B-tree * Dynamic partitioning is not only suitable for key range–partitioned data, but can equally well be used with hash-partitioned data. MongoDB since version 2.4 supports both key-range and hash partitioning, and it splits partitions dynamically in either case.